# La asignación en R son válidos 2 métodos '<-' o '='
x <- 7 # Definir variable (escalar) x que sea igual a 7
x # Mostrar que es x[1] 7y <- 3 + 2 * x # Crear y como funcion de x
y[1] 17class(y)[1] "numeric"
Los Datos en R se pueden clasificar por su dimensiones y los tipos de Datos que permiten almacenar, como se muestra en la siguiente tabla:
| Dimensiones | Homogéneos | Heterogéneos |
|---|---|---|
| 1d | Atomic vector | List |
| 2d | Matrix | Data frame |
| nd | Array |
Fuente: http://adv-r.had.co.nz/Data-structures.html
R nos permite definir variables que pueden ser luego usadas en las distintas operaciones. El lenguaje no solo permite definir escalares (variable de un numero), si no también variables que sean un conjunto de numero o caracteres ordenados.
# La asignación en R son válidos 2 métodos '<-' o '='
x <- 7 # Definir variable (escalar) x que sea igual a 7
x # Mostrar que es x[1] 7y <- 3 + 2 * x # Crear y como funcion de x
y[1] 17class(y)[1] "numeric"Números Random con decimales
ru <- runif(n = 100, min = 1, max = 10)
ru [1] 1.601020 2.254374 9.915688 3.724773 6.251265 1.281066 3.472568 6.904840
[9] 9.405628 9.944732 9.908071 6.875561 4.225559 7.314299 6.142009 9.741978
[17] 8.321103 3.882853 6.269609 4.029545 1.549212 5.857376 2.861688 1.491836
[25] 1.267138 3.663011 1.497060 1.660161 7.689715 3.976060 9.287646 5.500607
[33] 1.533130 8.152005 5.798118 7.572705 2.922966 6.702568 2.700091 3.884236
[41] 9.409226 7.840402 3.150096 1.643622 9.621524 4.190632 7.330470 8.490976
[49] 3.237444 8.549685 8.195388 5.074160 9.165808 3.876473 3.873793 9.535254
[57] 5.373759 5.217427 7.175068 2.467200 5.351309 4.278684 4.179086 9.844661
[65] 4.115072 9.737702 6.541612 4.686292 4.842401 7.996416 5.894151 6.020036
[73] 2.884828 7.267371 5.033462 3.167966 5.260955 6.374065 2.131451 9.886345
[81] 1.771088 6.906276 2.471112 2.318447 2.627581 3.914559 7.154508 3.664722
[89] 2.416142 6.301720 7.503638 7.804911 9.497792 2.771876 9.563302 4.053185
[97] 1.076836 2.405801 7.462381 9.277504hist(ru, breaks = 20, col = "orange", border = "gray60",
main = "Histograma de valores Random")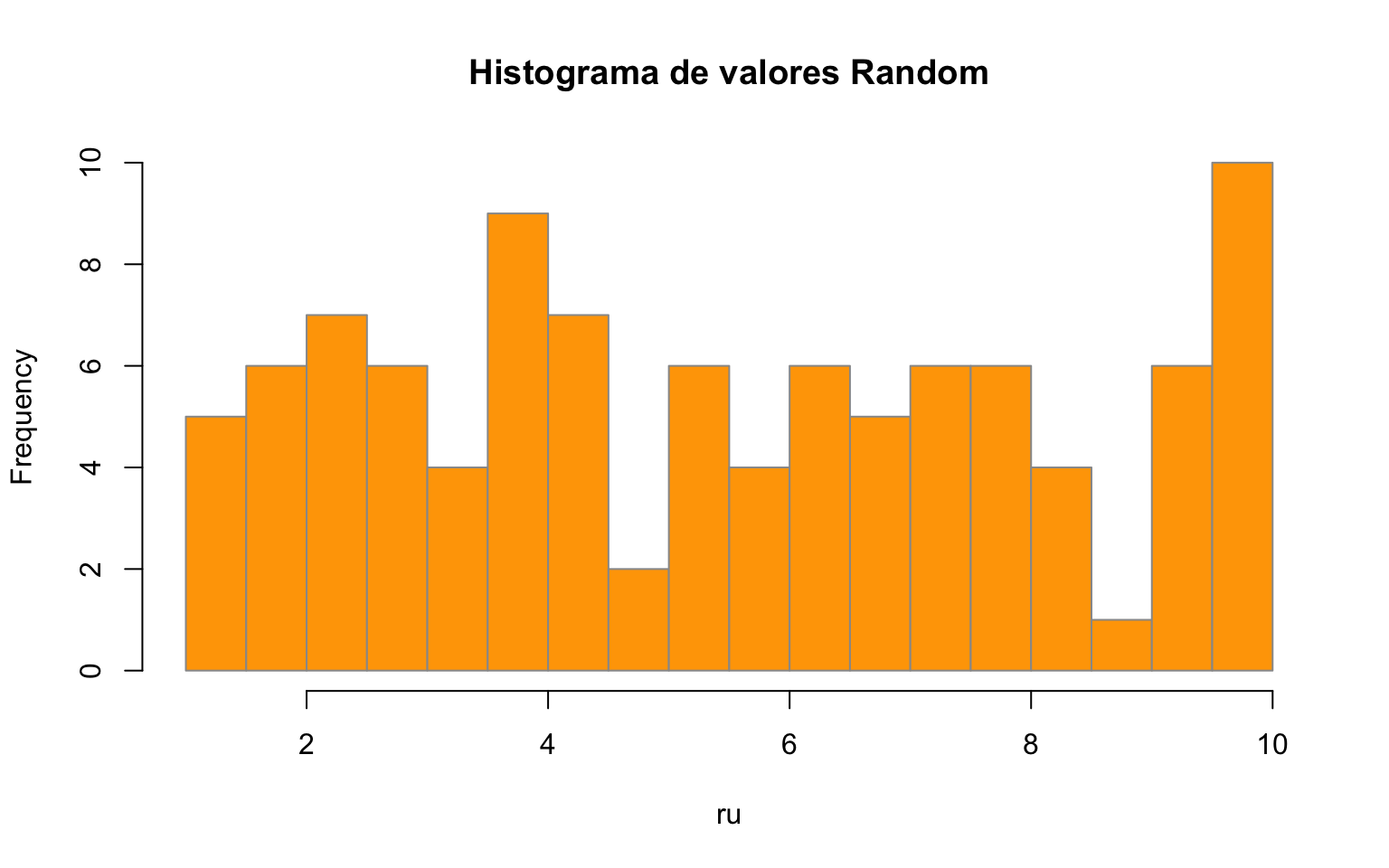
Números Random Enteros
Simular los lanzamientos de un dado
sample.int(n = 6, size = 10, replace = T) [1] 3 5 6 6 5 6 2 6 4 2ch <- "Chile" # Definir variable (objeto) ch que sea la palabra "Chile"
sn <- "Santiago"
ch # Mostrar ch[1] "Chile"sn[1] "Santiago"Unir variables de texto con paste()
ch <- "Chile" # Definir variable (objeto) ch que sea la palabra "Chile"
sn <- "Santiago"
union <- paste(sn,ch, sep = ", ")
union[1] "Santiago, Chile"Utilizar paste0()
union <- paste("Provincia de ", sn,ch, sep = ", ")
union[1] "Provincia de , Santiago, Chile"union0 <- paste0("Provincia de ", sn, ", ", ch)
union0[1] "Provincia de Santiago, Chile"Buscar y reemplazar con gsub
av <- "Av. Apoquindo"
comuna <- "comuna de Las Condes"
calle <- paste(av, comuna, union0, sep = ", ")
calle[1] "Av. Apoquindo, comuna de Las Condes, Provincia de Santiago, Chile"# reemplazar Av. por Avenida
calle_new <- gsub(pattern = "Av.", replacement = "Avenida", x = calle)
calle_new[1] "Avenida Apoquindo, comuna de Las Condes, Provincia de Santiago, Chile"Las variables pueden ser un conjunto de números y caracteres ordenados de varias maneras. El orden que se les da depende de lo que queremos lograr con estos.
Vector Cadenas unidimensionales (es decir una sola columna o fila) de un tipo único de valores (numéricos, caracteres, etc.)
vec <- c(4, 3, 1, 5, 8, 16)
vec[1] 4 3 1 5 8 16class(vec)[1] "numeric"str(vec) num [1:6] 4 3 1 5 8 16Podemos seleccionar parte del vector:
# EL primer índice en R es 1 (en otros lenguajes de programación es 0)
vec[3][1] 1La selección también puede ser hecha con una condición, de tal manera que solo seleccione aquella parte del vector que cumple con la condición.
Mayor a:
vec[vec >= 4][1] 4 5 8 16Contenido en:
vec[vec %in% c(3, 8, 7, 29)][1] 3 8Negación de la condición:
vec[!vec <= 3][1] 4 5 8 16También podemos realizar operaciones matemáticas simples aplicadas al vector, por ejemplo una suma:
vec2 <- c(7, 10, 1)
vec + vec2[1] 11 13 2 12 18 17Son estructuras eficientes y flexibles, que permiten combinar distintas clases de elementos :
lista <- list(1, 2, 3, "cosa", x, y)
lista[[1]]
[1] 1
[[2]]
[1] 2
[[3]]
[1] 3
[[4]]
[1] "cosa"
[[5]]
[1] 7
[[6]]
[1] 17str(lista)List of 6
$ : num 1
$ : num 2
$ : num 3
$ : chr "cosa"
$ : num 7
$ : num 17#Tambien se puede seleccionar parte de una lista, usando el doble corchete:
lista[[3]][1] 3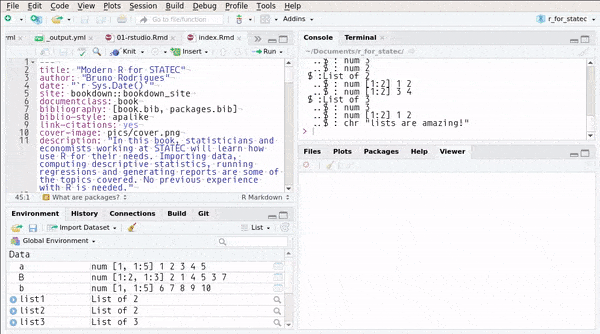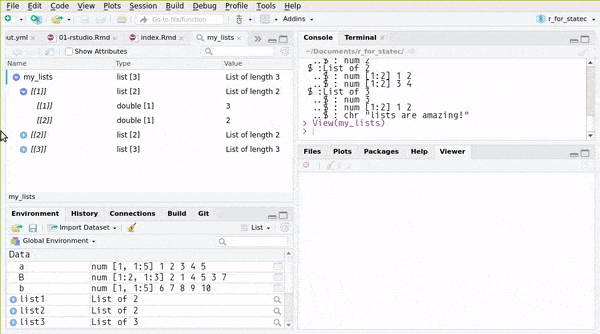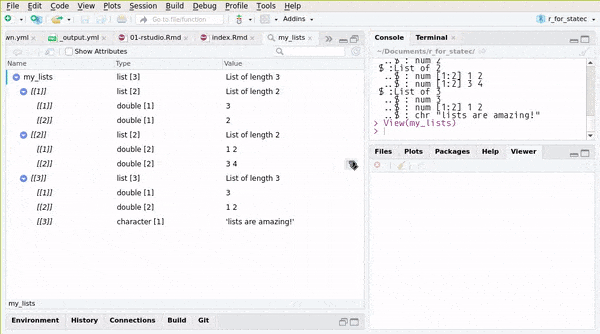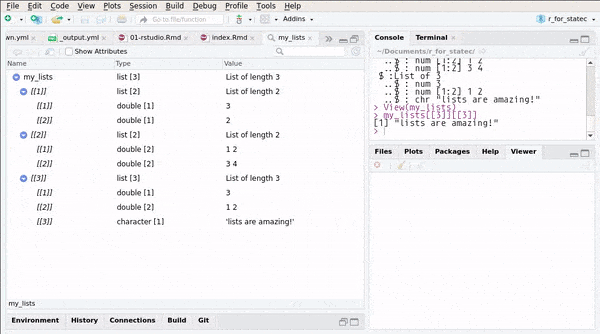
Son estructuras de datos con 2 dimensiones, horizontal y la vertical (filas y columnas). Podemos construirlas usando la función “matrix”, con un vector inicial y sus dimensiones:
n <- matrix(c(1.3, 2.8, 3.5,
6.4, 5.3, 6.2,
7, 4.5, 2.4,
6.3, 5.6, 5.3,
6.6, 7, 4.3),
nrow = 5, ncol = 3, byrow = TRUE)
n [,1] [,2] [,3]
[1,] 1.3 2.8 3.5
[2,] 6.4 5.3 6.2
[3,] 7.0 4.5 2.4
[4,] 6.3 5.6 5.3
[5,] 6.6 7.0 4.3La matriz tiene 2 dimensiones, por lo que para seleccionar partes de ella es necesario declarar dos dimensiones separadas por una coma. A la izquierda van las filas y a la derecha las columnas. Un valor vacío indica que se seleccionan todos los valores posibles.
n[1,2][1] 2.8n[,3][1] 3.5 6.2 2.4 5.3 4.3Estructura mas clásica de datos, es una matriz pero con mas atributos como nombres de columna y/o fila. Es lo mas similar en R a una tabla excel o la tabla de atributos. La manera mas simple de crear un dataframe es a partir de una matriz usando la función as.data.frame() :
df <- as.data.frame(n)
df V1 V2 V3
1 1.3 2.8 3.5
2 6.4 5.3 6.2
3 7.0 4.5 2.4
4 6.3 5.6 5.3
5 6.6 7.0 4.3Crear un dataframe desde cero
df <- data.frame(control_a = c(1.3, 6.4, 7, 6.3, 6.6),
control_b = c(2.8, 5.3, 4.5, 5.6, 7),
control_c = c(3.5, 6.2, 2.4, 5.3, 4.3))
df control_a control_b control_c
1 1.3 2.8 3.5
2 6.4 5.3 6.2
3 7.0 4.5 2.4
4 6.3 5.6 5.3
5 6.6 7.0 4.3Podemos consultar nombres a las columnas del dataframe
#consultar nombres de columans
names(df)[1] "control_a" "control_b" "control_c"# reasignar nombres de columnas
names(df)<- c("control_1","control_2","examen")
df control_1 control_2 examen
1 1.3 2.8 3.5
2 6.4 5.3 6.2
3 7.0 4.5 2.4
4 6.3 5.6 5.3
5 6.6 7.0 4.3Y a las filas del dataframe
df$alumno <- c("Sofia","Tomas","Luciano","Julian","Gabriela")
df control_1 control_2 examen alumno
1 1.3 2.8 3.5 Sofia
2 6.4 5.3 6.2 Tomas
3 7.0 4.5 2.4 Luciano
4 6.3 5.6 5.3 Julian
5 6.6 7.0 4.3 GabrielaTambién podemos realizar operaciones entre vectores del dataframe:
df$promedio_final <- 0.3*df$control_1 + 0.3*df$control_2 + 0.4*df$examen
df control_1 control_2 examen alumno promedio_final
1 1.3 2.8 3.5 Sofia 2.63
2 6.4 5.3 6.2 Tomas 5.99
3 7.0 4.5 2.4 Luciano 4.41
4 6.3 5.6 5.3 Julian 5.69
5 6.6 7.0 4.3 Gabriela 5.80